Компрессионные и маслосъемные кольца поршней двигателя. Как работает и почему изнашивается? | SUPROTEC
Всё это стало возможным благодаря постоянному совершенствованию цилиндро-поршневых групп, и в частности самих поршневых колец, от которых зависит стабильная и эффективная работа силового агрегата и возможность максимально продлить его ресурс.
Виды и назначение колец поршней двигателя
Эти детали представляют собой разомкнутые кольца, имеющие так называемые «замки». Они устанавливаются на внешнюю часть поршней в двигателях внутреннего сгорания. Главными их задачами являются:
- обеспечение герметичности самой камеры сгорания;
- удаление излишек тепла от деталей, в частности от поршня;
- создание условий для минимального расхода моторного масла.
По видам различают компрессионные и маслосъёмные кольца.
Компрессионные кольца. В свою очередь они делятся на верхние и нижние. Первые обеспечивают предварительную герметичность системы, а вторые – финишную герметичность работающего силового агрегата, когда газы уже прошли через верхние и промежуточные. В итоге отработанные газы не попадают в картер, уходят в выхлопную систему без всяких примесей, а двигатель работает равномерно, чётко и стабильно.
В итоге отработанные газы не попадают в картер, уходят в выхлопную систему без всяких примесей, а двигатель работает равномерно, чётко и стабильно.
Маслосъёмные кольца предназначены для удаления излишек моторного масла с поверхностей цилиндров. Они с одной стороны удаляют лишнее масло, а с другой оставляют тончайший слой масляной плёнки, для того чтобы максимально минимизировать силу трения между поршнями и цилиндрами.
Как компрессионные кольца двигателей, так и маслосъёмные могут быть изготовлены из следующих материалов:
- ковкого и пластичного чугуна – материала, который благодаря своей пористой структуре отлично удерживает масло, что, в свою очередь значительно снижает износ цилиндров;
- хромированного чугуна – материала, обладающего повышенной степенью устойчивости, но требующего прецизионной точности обработки;
- маркированной нержавеющей стали, обладающей аналогичными с чугуном характеристиками, которая производится по более простой, а значит и более дешёвой технологии;
- молибденового чугуна – дорогого материала, но при этом обеспечивающего наивысшую степень износоустойчивости, как правило, такие детали используются в элитных или уникальных сверхскоростных авто.


При изготовлении каждое изделие получается путём максимально точной резки трубы из чугуна или стали. При этом заготовка используется с сечением овальной формы. Именно такая форма обеспечивает необходимую эпюру давления на цилиндр, что обеспечивает гарантию полного прилегания детали и её надёжную приработку. Если бы в качестве заготовки была бы использована труба с круглым сечением, то готовые изделия попросту бы не прилегали в местах у замков.
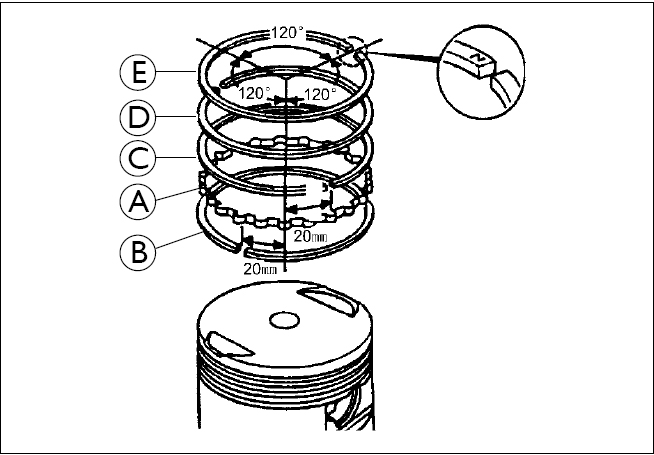
Кольца, установленные в канавках, разворачиваются таким образом, чтобы был образован угол между замками. Для трёх колец величина этого угла составляет 120°, а при двух – 180°.
В итоге получается, что эпюры давлений не совпадают, что обеспечивает равный износ по диаметру. Кроме того, таким образом обеспечивается так называемый «лабиринт», который снижает прорыв отработанных газов. Ранее для обеспечения равномерного угла между деталями на каждой из них были предусмотрены специальные фаски. Сегодня снижения силы трения добиваются посредством выпуска более тонких деталей, но при этом всё равно изделия выпускаются с ориентацией для установки.
Поломку легче предупредить, чем устранить. Используйте присадку для восстановления нормальной работы поршней и колец.
Основные неисправности и способы их устранения
Надо понимать, что поршневые компрессионные кольца, равно как и маслосъёмные являются расходными деталями, которые на определённом этапе времени требуют замены. Во время эксплуатации они подвергаются трению о поверхности цилиндров, высоким температурам, различным химическим воздействиям, например серы, что особенно характерно для дизельных двигателей.
В качестве основных причин возникновения неисправностей, связанных с этими деталями можно назвать потерю упругости из-за нарушений режима обкатки или использования неоригинальных колец низкого качества. Из-за плохого прилегания и прорывов горячих газов кольцо попросту «садится», чем ещё больше усугубляет проблему. Надо понимать, что эти детали всегда находятся в экстремальных условиях – на них постоянно действуют ударные нагрузки от искровой детонации, которые вызывают вибрацию кольца в канавке. В свою очередь это приводит к тому, что увеличивается зазор компрессионного кольца, а, следовательно, растёт вероятность поломок этой детали. Всё это ещё раз подтверждает тот факт, что кольца надо менять.
В свою очередь это приводит к тому, что увеличивается зазор компрессионного кольца, а, следовательно, растёт вероятность поломок этой детали. Всё это ещё раз подтверждает тот факт, что кольца надо менять.
На практике эти детали могут «ходить» до 500 тыс. и, наоборот, гораздо раньше изнашиваться. Всё зависит от стиля вождения, качества используемого топлива и моторного масла, стабильности и качества подготавливаемой воздушно-топливной смеси, своевременного обслуживания авто и многих других причин. Только вот, когда наступает это самое время замены, по каким признакам можно определить превышение допустимой степени износа, и можно ли максимально отложить ремонт? Эти вопросы возникают у автолюбителей чаще всего.
В технической документации на автомобиль каждый производитель указывает величину пробега, при которой требуется замена маслосъёмных и компрессионных колец поршня. Величины пробега для машин отечественного автопрома обычно находятся в пределах порядка 150 тыс. км, а для автомобилей ведущих мировых брендов – порядка 300 тыс. км. Эти цифры носят рекомендательный характер.
км, а для автомобилей ведущих мировых брендов – порядка 300 тыс. км. Эти цифры носят рекомендательный характер.
По каким внешним признакам можно определить, что нужна замена поршневых колец и замена компрессионных колец?
Ответ на этот вопрос не такой простой, как может показаться на первый взгляд. Дело в том, что внешние признаки неисправностей цилиндро-поршневых групп практически одинаковы, поэтому определить конкретную неисправность без «вскрытия» нереально. Общий подход такой. Если тяга резко уменьшилась, а нажатие на педаль газа не даёт достаточного ускорения, если мотор плохо запускается «на холодную» или даёт сбои при запуске «на горячую». Если замечено, что расход топлива увеличился, а из выхлопной трубы валит сизый или чёрный дым, то это свидетельствует об имеющейся неисправности. Потеря мощности говорит о снижении компрессии, сизый дым – повышенный расход масла, чёрный дым – перелив топлива. И не обязательно в этих случаях виноваты кольца.
В этих случаях вначале пытаются устранить проблему путём выставления правильного угла опережения зажигания, проверки и при необходимости замены свечей, диагностики работы датчика температуры охлаждающей жидкости, лямбда-зонда, другой электроники, отвечающей за подготовку смеси и правильную работу двигателя.
И только когда точно выявлено, что виновата поршневая группа, то приступают к ремонту, связанному с разборкой двигателя. При этом если автомобиль с большим пробегом, кроме устранения основной неисправности в случае большого износа колец, меняются и они.
Поломку легче предупредить, чем устранить. Используйте присадку для восстановления нормальной работы поршней и колец.
Основными неисправностями этих элементов можно назвать следующие:
– выламывание перегородок между канавками;
– заклинивание в канавках – наиболее часто встречающаяся проблема;
– вертикальные задиры;
– повышенный износ верхних компрессионных колец;
– следы диагонального контакта на юбке поршня;
– вымывание материала поршня в месте отверстия поршневого пальца;
Что касается признаков неисправности поршневых колец (ПК) и способов устранения, то нагляднее будет увидеть их в таблице:
Наименование неисправности | Признаки/причины | Способы устранения |
Выламывание перегородок между канавками ПК | Повышенный расход масла/Повышенное давление в камере сгорания, сильно увеличенная степень сжатия, слишком раннее зажигание. | Устранение причин, замена деталей, возможная замена ПК |
Заклинивание ПК в канавках – закоксовывание | Повышенный расход масла, потеря мощности/Слишком высокая температура сгорания смеси, возможно заклинивание поршня | Регулировка зажигания, регилировка топливно-воздушной смеси, замена повреждённых деталей |
Вертикальные задиры на ПК и юбке поршня | Повышенный расход масла/Абразивные материалы в масле | Очистка масляных каналов, замена масляного и воздушного фильтров. При повторном проявлении – замена ПК |
Повышенный износ верхних компрессионных колец | Перерасход масла, потеря мощности/Вымывание топлива из канавок ПК | Проверка системы впрыска, замена ПК. |
Следы диагонального контакта на юбке поршня | Повышений шум двигателя/Изгиб или перекос шатуна, «плавание» коленвала | Замена неисправных деталей, замена ПК |
Вымывание материала поршня в месте отверстия поршневого пальца | Повышенный шум в двигателе, перерасход масла/Неправильная установка или поломка стопорных колец | Регулировка, устранение несоосности пальца и коленвала, замена поршней и, соответственно, ПК |

Доказано, что износ поршневых колец прямо пропорционален запылённостью воздуха, который поступает в цилиндр. Заклинивание и закоксовывание колец случаются из-за скопления в канавках сажи, что является следствием применения некачественных моторных масел, несоблюдением сроков их замены, длительная езда с повышенным перерасходом масла из-за порванных или «задубевших» манжет клапанов. Часто возникают эти проблемы сразу после неправильного монтажа маслосъёмных колец при их замене. Есть вообще экзотические случаи неисправностей и просто поломок колец. Например, езда на растительном масле вместо качественной солярки.
Заклинивание и закоксовывание колец случаются из-за скопления в канавках сажи, что является следствием применения некачественных моторных масел, несоблюдением сроков их замены, длительная езда с повышенным перерасходом масла из-за порванных или «задубевших» манжет клапанов. Часто возникают эти проблемы сразу после неправильного монтажа маслосъёмных колец при их замене. Есть вообще экзотические случаи неисправностей и просто поломок колец. Например, езда на растительном масле вместо качественной солярки.
Можно ли избежать ремонта?
Может показаться, что всё очень удручающе – лезть внутрь двигателя для замены колец долго, сложно и недёшево. Однако есть выход. Сегодня на вопрос, можно ли избежать замены колец в случаях их закоксовывания, отвечает автохимия. Многие производители выпускают специальные средства, которые предназначены для решения этих проблем. Средства являются быстродействующими. Они способны возвращать подвижность кольцам, очищать цилиндры, поршни, камеры сгорания, выравнивать компрессию, снижать уровень вредных выхлопов.
Все они делятся на две группы. Первая – присадки в топливо, которые обеспечивают так называемую «мягкую» раскоксовку – очень простой способ, который обычно соединяется с заменой масла и масляного фильтра. Второй – средства для «жёсткого» способа, который рекомендуется для применения продвинутым автомобилистам или в условиях СТО.
Практика показывает, что использование этих средств при перегревах двигателя, появлении «дымления», повышенном расходе моторного масла, в подавляющем большинстве случаев решает проблему и исключает дорогостоящий ремонт.
Вывод простой. Если появилась проблема, то не надо сразу спешить заменять кольца или пытаться ремонтировать двигатель, ведь можно попытаться её устранить с помощью химической «раскоксовки» или использовать восстанавливающий триботехнический состав «СУПРОТЕК».
Кольца поршневой — что это, зачем они нужны и как работают?
Кольца поршневой — специально изготовленные металлические детали в форме окружности, которые одеваются на поршень, а цель поршневых колец — придание необходимого радиального давления для поддержания уплотнения между поршнем и цилиндром. Поршневые кольца, как правило, изготавливаются из такого сплава чугуна, который позволяет им быть упругими и в то же время пластичными, а также служить хорошими теплопроводниками.
Поршневые кольца, как правило, изготавливаются из такого сплава чугуна, который позволяет им быть упругими и в то же время пластичными, а также служить хорошими теплопроводниками.
Кольца одеваются на поршень в специально проделанный в нём паз. Сами кольца представляют собой незамкнутую окружность, что позволяет их одевать и снимать с поршня, не ломая их.
Почти во всех двигателях установлены 2 типа поршневых колец в зависимости от функции, которую они выполняют:
- Компрессионные кольца поршневой вставляются в специальные пазы в верхней части поршня. Их, как правило, насчитывается от 3 до 7 на одном поршне. Эти кольца главным образом служат для уплотнения между стенками цилиндра и поршнем и предотвращают проникновение смеси топлива и воздуха в такте сгорания в картер двигателя. Кроме того, ещё одна роль компрессионных колец поршневой заключается в передаче тепла от поршня к гильзе цилиндра, а также поглощения части поршневых колебаний из-за боковой тяги.
- Маслосъёмные кольца — это немного другие кольца поршневой, которые находятся ниже компрессионных колец. Маслосъёмные кольца обеспечивают идеальное смазывание стенки цилиндра, снимая бóльшую часть масла с поверхности гильзы в то время, когда поршень движется вниз. Это делается для того, чтобы свести к минимуму попадание масла в камеру сгорания и, как следствие, его расход.

Кольца поршневой группы очень упругие. Они самостоятельно регулируют свой диаметр, прижимаясь к цилиндру и в то же время оставаясь в своих пазах. Они также сводят к минимуму площадь контакта между поршнем и цилиндром и, таким образом, значительно уменьшают трение, которое в противном случае привело бы к износу поршневой и снижению КПД работы двигателя за счёт большого сопротивления, создаваемого эти трением.
Зачем нужны поршневые кольца?
Кольца поршневой позволяют использовать в поршнях очень лёгкие материалы, такие как алюминий, потому что среди требований к материалу поршней отпадает стойкость к трению, ведь его выполняют кольцо.
Только представьте, если бы у Вашего автомобиля в моторе не было бы колец, и поршень бы тёрся напрямую о стенки цилиндра. Что бы было тогда? Ну, во-первых, поршень должен бы был иметь тот же размер, что и цилиндры. Но тут нас ждала бы большая проблема: при нагреве поршень расширяется в диаметре, и, таким образом, он мог бы застрять в цилиндре, что привело бы к дорогостоящему ремонту. Во-вторых, такой поршень очень быстро бы вызывал всё больше и больше потери компрессии за счёт быстрого износа. Именно поэтому кольца поршневой выполняют такую важную роль.
Процесс монтажа кольца на поршень
Подводя итог, отметим, что кольца в двигателе выполняют 4 главные функции:
- Компрессия. Поршневые кольца поддерживают изоляцию камеры сгорания от картерного пространства, что позволяет проводить более эффективное сжатие топлива в камере. Т.е. газообразные продукты сгорания, возникающие в момент зажигания, не проходят сквозь цели между поршнем и цилиндром, потому что от возникновения таких щелей защищает кольцо.
- Экономия расхода масла. Маслосъёмные кольца снимают часть масла со стенок цилиндра во время работы мотора, благодаря чему компрессионные кольца отлично смазывают, и в то же время излишки масла не попадают в камеры сгорания.
- Теплообмен. Поршневые кольца передают тепло от поршня к цилиндру. Когда топливно-воздушная смесь возгорается в камер сгорания, температура внутри неё достигает приблизительно 300 °С. Если тепло будет накапливаться внутри поршня, двигатель может быть повреждён.
- Погашение горизонтальных колебаний поршня. Плотно прижимаясь к стенкам цилиндра, кольца поршневой не дают поршню «гулять» в горизонтальных направлениях, что предотвращает износ поршневой группы мотора.

Маслосъемные кольца – устраняем проблемы в цилиндрах
Маслосъемные кольца и колпачки иногда называют самыми важными элементами двигателя. Разберемся, что это за детали, где находятся и как производится замена –чтобы в любой момент оказать первую помощь своему железному коню.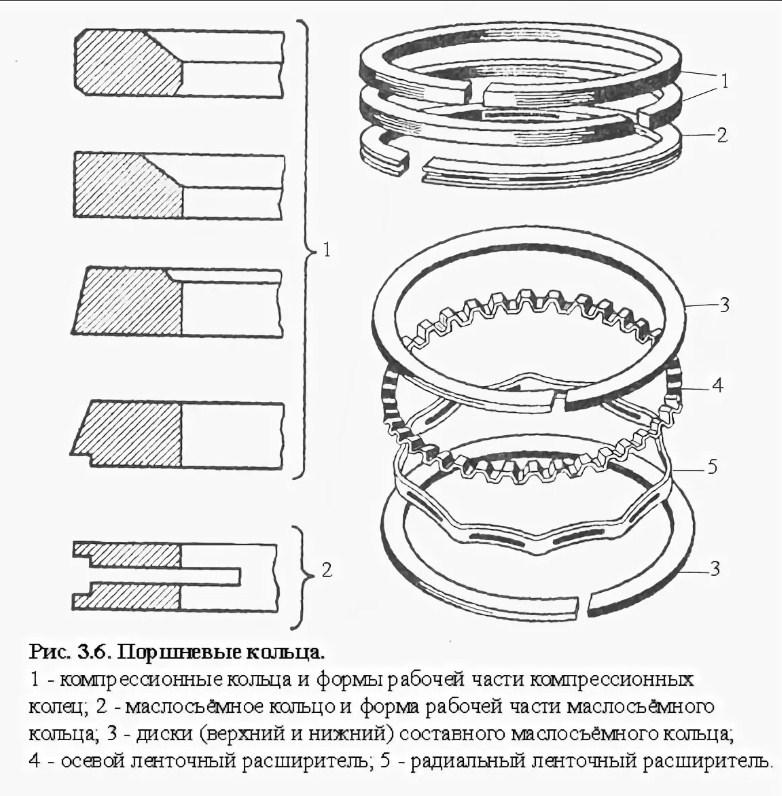
Знакомимся с маслосъемными кольцами
Итак, поршневые кольца, к которым относятся и маслосъемные, играют огромную роль в устройстве транспортного средства. Состоит этот комплект из трех элементов: верхнее компрессионное, компрессионно-маслосъемное и нижнее маслосъемное кольцо.
Итак, главная функция таких колец – отвод теплоты от поршня. В противном случае на нем появятся различные дефекты – прогары, задиры – что приведет к некорректной работе. Деталь будет заклинивать в цилиндре. Еще благодаря им обеспечивается герметичность камеры сгорания, а следовательно, минимизируется перемещение газов из цилиндра в картер и в обратном направлении. Кроме того, регулируется смазывание сопрягаемых элементов. Ведь и масляное голодание, и его избыток приводят к негативным последствиям.
Прежде чем говорить о неисправностях, замене и раскоксовке маслосъемных колец, уделим немного внимания их конструкционным особенностям. Неразъемные детали на сегодняшний день утратили свою популярность и даже сняты с производства. Из-за повышенной жесткости они не могут достаточно прилегать к поверхности и тщательно удалять масло.
Существуют детали, состоящие из двух и трех частей. В комплект первых входит само кольцо и спиральная пружина. К их достоинствам относится повышенная гибкость, благодаря которой обеспечивается плотное прилегание к стенкам цилиндра. Пружина настолько прижимается к внутренней стороне кольца, что конструкция получается цельной. Трехэлементные кольца состоят из распорной пружины и двух стальных пластинок. В основном они нашли свое применение в бензиновых моторах. К плюсам следует отнести максимально плотное прилегание по всему периметру.
Рабочий день маслосъемных колец
Самая большая нагрузка приходится на компрессионное кольцо, поэтому его изготавливают преимущественно из специальных легированных материалов. Также на его поверхность наносится износостойкое покрытие, ведь этот элемент должен выдержать давление газов и высокую температуру. Так, по мере приближения к верхней критической точке количество смазки уменьшается, а увеличение давления в цилиндре способствует более плотному прилеганию кольца к стенкам. Снижается и скорость движения, а полная остановка вовсе приводит к разрыву маслянистой пленки. Другими словами, деталь работает в режиме сухого трения, а значит, изнашивается очень быстро.
Среднее кольцо испытывает гораздо меньшие нагрузки. Оно производится из легированного чугуна. Для форсированных двигателей на компрессионно-маслосъемные элементы наносят износостойкое покрытие. Дело в том, что у замка повышенное давление сохраняется. Из названия понятно, что они выполняют не только компрессионные функции, но еще и принимают участие в управлении смазкой. Чтобы исключить вероятность попадания масла в камеру сгорания, наружная поверхность имеет коническую форму с углом наклона не более 0°80’. Главная задача таких элементов – снимать масло со стенок во время движения вниз и не давать ему попасть в камеру сгорания при ходе вверх.
Из названия понятно, что они выполняют не только компрессионные функции, но еще и принимают участие в управлении смазкой. Чтобы исключить вероятность попадания масла в камеру сгорания, наружная поверхность имеет коническую форму с углом наклона не более 0°80’. Главная задача таких элементов – снимать масло со стенок во время движения вниз и не давать ему попасть в камеру сгорания при ходе вверх.
Последние элементы отвечают только за снятие масла и отвод его в картер. Чтобы справиться с поставленной задачей максимально качественно, конструкцией предусмотрено два пояска, каждый из которых снимает остатки масла. В результате и между этими поясками, и на нижней кромке детали собирается жидкость. Чтобы ее устранить, нижние колпачки имеют продолговатые прорези либо отверстия, по которым вещество выводится на обратную сторону. Далее уже оно попадает в специальный поддон или на внешнюю сторону поршня.
Залегание или износ – когда пора проверить состояние колец?
Как видно, условия работы поршневых колпачков и колец нелегкие и поэтому естественного износа не избежать. Обычно комплекта хватает на 150 тысяч километров, хотя некоторые автовладельцы утверждают, что их двигатели проходят и по 500 тыс. км. Но о таких показателях можно говорить только при правильной эксплуатации автомобиля, в противном случае задуматься о ремонте движка придется намного раньше. Использование некачественного либо неподходящего масла и его несвоевременная замена негативно скажется на состоянии колец, что приблизит их залегание. Кроме того, необходимо следить за состоянием воздушного фильтра, особенно если приходится постоянно ездить по сильно запыленной местности. Немаловажна и исправность топливного фильтра.
Обычно комплекта хватает на 150 тысяч километров, хотя некоторые автовладельцы утверждают, что их двигатели проходят и по 500 тыс. км. Но о таких показателях можно говорить только при правильной эксплуатации автомобиля, в противном случае задуматься о ремонте движка придется намного раньше. Использование некачественного либо неподходящего масла и его несвоевременная замена негативно скажется на состоянии колец, что приблизит их залегание. Кроме того, необходимо следить за состоянием воздушного фильтра, особенно если приходится постоянно ездить по сильно запыленной местности. Немаловажна и исправность топливного фильтра.
Желательно не перегревать и не перегружать сам двигатель. Образование нагара в поршневых канавках приводит к залеганию маслосъемных колец. В этом случае поршень недостаточно плотно прилегает к цилиндру и автомобиль не может развивать необходимую мощность. Можно максимально отсрочить залегание маслосъемного кольца. Избегайте кратковременных поездок в зимнее время, так как движок не успевает прогреться до нужной температуры. Очень опасно в этот период давать и чрезмерные нагрузки. Если в системе не будет достаточно смазки, произойдет перегрев. Он приведет к заклиниванию и образованию на поверхностях поршня и цилиндра различных дефектов. В результате колпачки могут полностью испортиться, либо разрушатся перегородки между канавками. Опасны для автомобиля и постоянные простои в городских пробках.
Очень опасно в этот период давать и чрезмерные нагрузки. Если в системе не будет достаточно смазки, произойдет перегрев. Он приведет к заклиниванию и образованию на поверхностях поршня и цилиндра различных дефектов. В результате колпачки могут полностью испортиться, либо разрушатся перегородки между канавками. Опасны для автомобиля и постоянные простои в городских пробках.
Определить необходимость ремонта либо замены можно по следующим признакам износа маслосъемных колец. Значительно увеличится расход масла, может появляться сизый дым – во время начала движения после кратковременной остановки, например, на светофорах. Кроме того, тревожные признаки износа – протечки и испарения масла через уплотнительные прокладки, сальники (колпачки) и в прочих местах. Обратите внимание на цвет этой жидкости, если вы ее только поменяли, а она почернела, то замена уплотнителей неизбежна. Еще следует проверить свечи, они должны быть чистыми, в противном случае придется обращаться на СТО либо проводить ремонтные работы самостоятельно.
Итак, если вы обнаружили у своего авто какие-либо признаки износа, то нужно проверять маслосъемные кольца. Диагностика колпачков проводится достаточно просто. Необходимо отсоединить шланг системы принудительной вентиляции. Если давление картерных повышено, то дело в износе колпачков.
Раскоксовка и ее значение
Но всегда ли необходима полная замена деталей или можно как-то продлить их жизнь? В случае нагара и залегания колец нередко помогает раскоксовка. Опытные мотористы делятся следующим рецептом восстановления подобных элементов без демонтажа. Готовится смесь из ацетона и керосина в равных долях. Затем следует вывернуть свечи зажигания и залить раскоксовыватель в цилиндр через образовавшиеся отверстия. Оставляем на 9 часов. По истечении времени устанавливаем свечи на их штатные места, заводим двигатель и катаемся на максимальных оборотах (достаточно пробега 10–15 км). После очень желательна замена масла и фильтра.
После очень желательна замена масла и фильтра.
Можно также приобрести специальные раскоксовыватели маслосъемных колец, тем более сегодня нет дефицита подобной химии. В принципе, их применение схоже между собой и с предыдущим способом, но есть некоторые отличия, поэтому обязательно изучите инструкцию. Рассмотрим одну из схем раскоксовки специальной жидкостью. Приподнимаем домкратом переднюю часть переднеприводных авто, для заднеприводных, соответственно, заднюю. Выкручиваем свечи и выставляем поршни в среднее положение. Для этого необходимо включить последнюю передачу и, прокручивая за колесо движок, определить положение поршней. Затем заливаем раскоксовыватель в свечные отверстия. Раскисление нагара происходит обычно за 15 минут, хотя не забывайте уточнить это время в инструкции.
Чтобы помочь жидкости раскоксовать всю поверхность, прокручивайте колесо, меняйте угол поворота. Но не беспрерывно – несколько раз пошевелили, дали отдохнуть пару минут, затем повторяете процедуру.

Чтобы исключить пробой катушки зажигания во время прокручивания движка, следует снять центральный высоковольтный провод и закрепить его где-нибудь в безопасном месте, при этом не забываем выдерживать расстояние минимум 5 см до массы и металлического наконечника провода. Следующий шаг – прокрутка движка стартером при отключенной передаче. Достаточно 10 секунд. Этот этап необходим, ведь только так можно выкинуть из цилиндра оставшийся раскоксовыватель. Если этого не делать, то после заведения мотора может произойти гидравлический удар, что чревато выходом из строя всего силового агрегата. Раскоксовка завершена, теперь осталось вернуть все на штатные места и завести авто. Не бойтесь, если движок не сразу отреагирует, помогайте ему газом. Также вас не должен смущать сильный дым из выхлопной трубы. Заведите авто и дайте ему поработать на холостых оборотах еще 15 минут.
Замена по шагам – помощь дилетанту
Раскоксовка помогает только в случае с нагаром, если же речь идет об износе, то спасет только замена. Ее можно делать своими руками. Нам понадобится специальный съемник, оправка для запрессовки, металлический прутик, еще не обойтись без пинцета и рассухаривателя. Приобретая новые колпачки и кольца, отдавайте предпочтение качеству – ищите оригинальные детали. Помните, если попадете на подделку, то правильной работой движка можно насладиться всего несколько тысяч километров. Кроме того, покрытие верхних колец иногда подбирается под материал двигателя. Да и компрессионно-маслосъемные элементы должны соответствовать материалу гильзы цилиндра. Если замена будет произведена более дешевыми аналогами, то результат может получиться отрицательным.
Ее можно делать своими руками. Нам понадобится специальный съемник, оправка для запрессовки, металлический прутик, еще не обойтись без пинцета и рассухаривателя. Приобретая новые колпачки и кольца, отдавайте предпочтение качеству – ищите оригинальные детали. Помните, если попадете на подделку, то правильной работой движка можно насладиться всего несколько тысяч километров. Кроме того, покрытие верхних колец иногда подбирается под материал двигателя. Да и компрессионно-маслосъемные элементы должны соответствовать материалу гильзы цилиндра. Если замена будет произведена более дешевыми аналогами, то результат может получиться отрицательным.
Следующим этапом замены маслосъемных колец и колпачков будет демонтаж узлов и механизмов, чтобы обеспечить доступ к деталям. Первым снимается воздушный фильтр, потом топливный насос. Не забываем и о распределителе зажигания. Чтобы демонтировать корпус привода для вспомогательных агрегатов, необходимо разъединить болтовое соединение, потом снимаем с аккумулятора минусовую клемму, а с распределительного вала зубчатый шкив.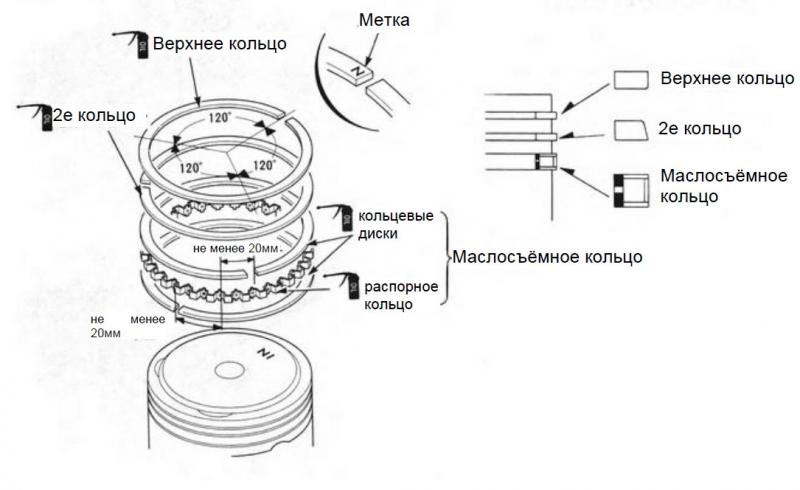 Далее, чтобы добраться до крышки головки блока, снимаем привод массы. В последнюю очередь откручиваются гайки, фиксирующие передний и задний корпус подшипников распределительного вала.
Далее, чтобы добраться до крышки головки блока, снимаем привод массы. В последнюю очередь откручиваются гайки, фиксирующие передний и задний корпус подшипников распределительного вала.
Нельзя игнорировать положение шпонки распредвала, если она посажена недостаточно плотно, то ее также необходимо демонтировать, иначе можно потерять. Теперь освободился доступ и к самому распределительному валу, вынимаем его и сальник. Теперь разворачиваем деталь, чтобы поршень оказался в ВМТ, и, вынув свечу, вставляем в образовавшееся отверстие металлический прутик, иначе клапан провалится. Затем специальным инструментом сжимаем пружины клапана и вынимаем с помощью пинцета два сухаря. Выпрессовываем кольца с помощью приспособления.
Теперь установка. С новых запчастей снимаем пружины, чтобы не повредить их. Перед монтажом не забудьте смазать элементы моторным маслом. Запрессовываем деталь и ставим пружины на место. Установку маслосъемных колец следует проводить строго в обратной последовательности. При монтаже средних очень важно не перепутать стороны, иначе расход масла значительно возрастет.
При монтаже средних очень важно не перепутать стороны, иначе расход масла значительно возрастет.
15 лучших инструментов для извлечения данных из Интернета в 2021 году
- Home
Testing
- Back
- Agile Testing
- BugZilla
- Cucumber
- Database Testing
- 9000 J2000 Тестирование базы данных 9000
- Назад
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- Центр качества SAP
- SoapUI
- Управление тестированием
- TestLink
SAP
- Назад 900 03 ABAP
- APO
- Начинающий
- Basis
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- Crystal Reports
- FICO3
- Заработная плата
- Назад
- PI / PO
- PP
- SD
- SAPUI5
- Безопасность
- Менеджер решений
- Successfactors
- SAP Back Tutorials
- 9007
- Apache
- AngularJS
- ASP. Net
- C
- C #
- C ++
- CodeIgniter
- СУБД
- JavaScript
- Назад
- Java
- JSP
- Kotlin
- Linux
- Linux
- Kotlin
- Linux
js- Perl
 Net
Net- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL 0000003 SQL000
- SQL 000
- UML
- VB.Net
- VBScript
- Веб-службы
- WPF
Обязательно учите!
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Бизнес-аналитик
- Создание веб-сайта
- Облачные вычисления
- COBOL
- Встроенные системы
- 0003
- 9000 Эталонный дизайн 900 Ethical
- Учебные пособия по Excel
- Программирование на Go
- IoT
- ITIL
- Jenkins
- MIS
- Сеть
- Операционная система
- Назад
- Prep
- Управление проектом
- Prep
- PM Salesforce
- SEO
- Разработка программного обеспечения
- VBA
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Хранилище данных
- DevOps Back
- HBase
- HBase веб-скребок от начала до конца
Что такое веб-скребок?
Веб-парсер — это программа, которая буквально очищает или собирает данные с веб-сайтов.
Возьмем приведенный ниже гипотетический пример, в котором мы могли бы создать веб-парсер, который будет заходить в твиттер и собирать содержимое твитов.В приведенном выше примере мы можем использовать парсер для сбора данных из Twitter. Мы можем ограничить собираемые данные твитами на определенную тему или от конкретного автора. Как вы можете себе представить, данные, которые мы собираем из веб-парсера, в значительной степени будут определяться параметрами, которые мы даем программе при ее создании. Как минимум, у каждого проекта парсинга веб-страниц должен быть URL, с которого будет производиться парсинг.В этом случае URL-адрес будет twitter.com. Во-вторых, веб-парсер должен знать, в каких тегах искать информацию, которую мы хотим очистить. В приведенном выше примере мы видим, что у нас может быть много информации, которую мы не хотели бы очищать, например заголовок, логотип, навигационные ссылки и т. Д. Большинство реальных твитов, вероятно, будет в теге абзаца, или иметь определенный класс или другую идентифицирующую функцию.
Чтобы узнать, как определить, где находится информация на странице, требуется небольшое исследование, прежде чем мы создадим парсер.На этом этапе мы можем создать парсер, который будет собирать все твиты на странице. Это может быть полезно. Или мы могли бы дополнительно отфильтровать царапину, но указав, что мы хотим очищать твиты только в том случае, если они содержат определенный контент. По-прежнему глядя на наш первый пример, нас может заинтересовать сбор только твитов, в которых упоминается определенное слово или тема, например «Губернатор». Возможно, будет проще собрать большую группу твитов и позже проанализировать их на сервере. Или мы могли бы заранее отфильтровать некоторые результаты.
Чем полезны парсеры?
В первом разделе мы частично ответили на этот вопрос. Веб-скрапинг может быть таким же простым, как идентификация содержимого с большой страницы или нескольких страниц информации. Однако одна из замечательных особенностей веб-скрапинга заключается в том, что он дает нам возможность не только идентифицировать полезную и актуальную информацию, но и позволяет нам сохранять эту информацию для дальнейшего использования.
В приведенном выше примере мы могли бы захотеть сохранить данные, которые мы собрали из твитов, чтобы мы могли видеть, когда твиты были наиболее частыми, каковы были наиболее распространенные темы или какие люди упоминались чаще всего.Какие предварительные условия необходимы для создания парсера?
Прежде чем мы углубимся в основные принципы работы веб-скребка, давайте сделаем шаг назад и поговорим о том, какое место занимает веб-скребок в более широкой экосистеме веб-технологий. Взгляните на простой рабочий процесс, представленный ниже:
Основная идея веб-скрейпинга заключается в том, что мы берем существующие HTML-данные, используя веб-скребок для идентификации данных, и конвертируем их в полезный формат. Конечным этапом является сохранение этих данных в формате JSON или в другом полезном формате.Как видно из диаграммы, мы могли бы использовать любую технологию, которую мы предпочитаем для создания настоящего веб-парсера, такую как Python, PHP или даже Node, и это лишь некоторые из них.
В этом примере мы сосредоточимся на использовании Python и сопутствующей ему библиотеки Beautiful Soup. Здесь также важно отметить, что для создания успешного веб-парсера нам необходимо хотя бы в некоторой степени быть знакомыми со структурами HTML и форматами данных, такими как JSON.Чтобы убедиться, что все мы находимся на одной странице, мы подробно рассмотрим каждое из этих предварительных условий, так как важно понимать, как каждая технология вписывается в проект веб-парсинга.Необходимые условия, о которых мы поговорим дальше:
- HTML-структуры
- Основы Python
- Библиотеки Python
- Хранение данных в виде JSON (объектная нотация JavaScript)
Если вы уже ознакомившись с любым из них, можете пропустить.
1. HTML-структуры
1.a. Определение тегов HTML
Если вы не знакомы со структурой HTML, лучше всего начать с открытия инструментов разработчика Chrome.
В других браузерах, таких как Firefox и Internet Explorer, также есть инструменты разработчика, но в этом примере я буду использовать Chrome. Если вы нажмете на три вертикальные точки в правом верхнем углу браузера, затем выберите «Дополнительные инструменты», а затем «Инструменты разработчика», вы увидите всплывающую панель, которая выглядит следующим образом:Мы можем быстро увидеть, как структурирован текущий HTML-сайт. Весь контент, содержащийся в определенных «тегах». Текущий заголовок находится в теге «
», а большинство абзацев — в тегах «
».Каждый из тегов также имеет другие атрибуты, такие как «класс» или «имя». Нам не нужно знать, как создать сайт HTML с нуля. При создании веб-парсера нам нужно знать только базовую структуру Интернета и то, как идентифицировать определенные веб-элементы. Chrome и другие инструменты разработчика браузеров позволяют нам видеть, какие теги содержат информацию, которую мы хотим очистить, а также другие атрибуты, такие как «класс», которые могут помочь нам выбрать только определенные элементы.
Давайте посмотрим, как может выглядеть типичная структура HTML:
Это похоже на то, что мы только что рассмотрели в инструментах Chrome dev.Здесь мы видим, что все элементы HTML содержатся в открывающем и закрывающем тегах body. У каждого элемента также есть свой открывающий и закрывающий теги. Элементы, которые вложены или имеют отступ в структуре HTML, указывают на то, что элемент является дочерним элементом своего контейнера или родительским элементом. Как только мы начнем создавать наш веб-скребок Python, мы также можем идентифицировать элементы, которые мы хотим очистить, основываясь не только на имени тега, но и на том, является ли этот элемент дочерним по отношению к другому элементу. Например, здесь мы видим, что в этой структуре есть тег
- , указывающий на неупорядоченный список.Каждый элемент списка
- является дочерним по отношению к родительскому тегу
- . Если бы мы хотели выбрать и очистить весь список, мы могли бы указать Python захватить все дочерние элементы тега
- .
Элементы HTML
Теперь давайте подробнее рассмотрим элементы HTML. Основываясь на предыдущем примере, вот наш
или элемент заголовка:
Очень важно знать, как указать, какие элементы мы хотим очистить. Например, если бы мы сказали Python, что нам нужен элемент
, это было бы хорошо, если на странице нет нескольких элементов
.Если нам нужен только первый
или последний, нам может потребоваться конкретизировать, чтобы сообщить Python, что именно мы хотим. Большинство элементов также предоставляют нам атрибуты «class» и «id». Если бы мы хотели выбрать только этот элемент
, мы могли бы сделать это, сказав Python, по сути, «Дайте мне элемент
с классом myClass». Селекторы ID еще более специфичны, поэтому иногда, если атрибут класса возвращает больше элементов, чем мы хотим, выбор с помощью атрибута ID может помочь.
2. Основы Python
2.a. Настройка нового проекта
Одним из преимуществ создания парсера на Python является то, что синтаксис Python прост и понятен.
Мы могли бы начать работу за считанные минуты с помощью веб-парсера Python. Если вы еще не установили Python, сделайте это сейчас:Нам также нужно будет выбрать текстовый редактор. Я использую ATOM, но есть много других похожих вариантов, которые делают относительно одно и то же.Поскольку веб-парсеры довольно просты, выбор текстового редактора полностью зависит от нас. Если вы хотите попробовать ATOM, скачайте его здесь:
Теперь, когда у нас установлен Python и мы используем текстовый редактор по нашему выбору, давайте создадим новую папку проекта Python. Сначала перейдите туда, где мы хотим создать этот проект. Я предпочитаю выкидывать все на свой уже перегруженный рабочий стол. Затем создайте новую папку и внутри папки создайте файл.Назовем этот файл webscraper.py. Мы также хотим создать второй файл с именем «parsedata.py» в той же папке. На данный момент у нас должно быть что-то похожее на это:
Одно очевидное отличие состоит в том, что у нас еще нет данных.
Это будут данные, полученные из Интернета. Если мы подумаем о том, каким может быть наш рабочий процесс для этого проекта, мы можем представить, что он выглядит примерно так:Во-первых, есть необработанные данные HTML, которые есть в Интернете. Затем мы используем программу, созданную на Python, для очистки / сбора нужных нам данных.Затем данные сохраняются в формате, который мы можем использовать. Наконец, мы можем проанализировать данные, чтобы найти соответствующую информацию. И парсинг, и парсинг будут обрабатываться отдельными скриптами Python. Первый будет собирать данные. Второй будет анализировать собранные нами данные.
Если вам удобнее настраивать этот проект через командную строку, смело делайте это.
2.b. Виртуальные среды Python
Мы еще не закончили настройку проекта. В Python мы часто используем библиотеки как часть нашего проекта.Библиотеки похожи на пакеты, которые содержат дополнительные функции для нашего проекта. В нашем случае мы будем использовать две библиотеки: Beautiful Soup и Requests.
Библиотека запросов позволяет нам делать запросы к URL-адресам и получать доступ к данным на этих HTML-страницах. Beautiful Soup содержит несколько простых способов идентифицировать теги, которые мы обсуждали ранее, прямо из нашего скрипта Python.Если бы мы установили эти пакеты на наши машины глобально, мы могли бы столкнуться с проблемами, если бы продолжали разрабатывать другие приложения.Например, одна программа может использовать библиотеку запросов версии 1, а более позднее приложение может использовать библиотеку запросов версии 2. Это может вызвать конфликт, затрудняющий запуск одного или обоих приложений.
Чтобы решить эту проблему, рекомендуется создать виртуальную среду. Эти виртуальные среды подобны капсулам для приложения. Таким образом, мы могли бы запускать версию 1 библиотеки в одном приложении и версию 2 в другом, без конфликтов, если бы мы создали виртуальную среду для каждого приложения.
Сначала давайте вызовем окно терминала, так как следующие несколько команд проще всего выполнять из терминала.
В OS X мы откроем папку Applications, а затем папку Utilities. Откройте приложение Терминал. Мы также можем добавить это в нашу док-станцию.В Windows мы также можем найти терминал / командную строку, открыв меню «Пуск» и выполнив поиск. Это просто приложение, расположенное в C: \ Windows \ System32.
Теперь, когда у нас открыт терминал, мы должны перейти в папку нашего проекта и использовать следующую команду для создания виртуальной среды:
python3 -m venv tutorial-env
Этот шаг создает виртуальную среду, но сейчас это просто спящий.Чтобы использовать виртуальную среду, нам также необходимо ее активировать. Мы можем сделать это, выполнив следующую команду в нашем терминале:
На Mac:
source tutorial-env / bin / activate
Или Windows:
tutorial-env \ Scripts \ activate.bat
3 библиотеки Python
3.a. Установка библиотек
Теперь, когда наша виртуальная среда настроена и активирована, нам нужно установить библиотеки, о которых мы упоминали ранее.
Для этого мы снова воспользуемся терминалом, на этот раз установив библиотеки с помощью установщика pip.Выполним следующие команды:Установить Beautiful Soup:
Запросы на установку:
И все готово. Что ж, по крайней мере, у нас есть среда и библиотеки.
3.b. Импорт установленных библиотек
Сначала давайте откроем наш файл webscraper.py. Здесь мы настроим всю логику, которая будет запрашивать данные с сайта, который мы хотим очистить.
Самое первое, что нам нужно сделать, это сообщить Python, что мы фактически собираемся использовать только что установленные библиотеки.Мы можем сделать это, импортировав их в наш файл Python. Было бы неплохо структурировать наш файл так, чтобы весь наш импорт происходил в верхней части файла, а вся наша логика выполнялась бы потом. Чтобы импортировать обе наши библиотеки, мы просто включим следующие строки в верхней части нашего файла:
из bs4 import BeautifulSoup
import requestsЕсли бы мы хотели установить другие библиотеки в этот проект, мы могли бы сделать это через pip, а затем импортируйте их в начало нашего файла.
Следует помнить, что некоторые библиотеки довольно большие и могут занимать много места. Развернуть сайт, над которым мы работали, может быть сложно, если на нем слишком много больших пакетов.3.c. Библиотека запросов Python
Запросы с Python и Beautiful Soup в основном состоят из трех частей:
URL, ОТВЕТ И КОНТЕНТ.
URL-адрес — это просто строка, содержащая адрес HTML-страницы, которую мы собираемся очистить.
ОТВЕТ является результатом запроса GET.Фактически мы будем использовать здесь переменную URL в запросе GET. Если мы посмотрим на ответ, то на самом деле это код состояния HTTP. Если запрос был успешным, мы получим успешный код статуса, например 200. Если возникла проблема с запросом или сервер не отвечает на сделанный нами запрос, код статуса может быть неудачным. Если мы не получаем то, что хотим, мы можем найти код состояния, чтобы определить, в чем может заключаться ошибка. Вот полезный ресурс, чтобы узнать, что означают коды, на случай, если нам действительно понадобится их устранить:
Наконец, СОДЕРЖАНИЕ — это содержание ответа.
Если мы напечатаем все содержимое ответа, мы получим все содержимое на всей странице запрашиваемого URL.4. Сохранение данных в виде JSON
Если вы не хотите тратить время на очистку и хотите сразу перейти к манипулированию данными, вот несколько наборов данных, которые я использовал для этого упражнения:
https: // www .dropbox.com / s / v6vjffuakehjpic / stopwords.json? dl = 0
https://www.dropbox.com/s/2wqibsa5fro6gpx/tweetsjson.json?dl=0
https://www.dropbox.com/s / 1zwynoyjg15l4gv / twitterData.json? dl = 04.a. Просмотр очищенных данных
Теперь, когда мы более или менее знаем, как будет настроен наш парсер, пора найти сайт, который мы действительно можем очистить. Ранее мы рассмотрели несколько примеров того, как может выглядеть скребок для твиттера, и некоторые варианты использования такого парсера. Однако мы, вероятно, не будем собирать Twitter здесь по нескольким причинам. Во-первых, всякий раз, когда мы имеем дело с динамически генерируемым контентом, как в случае с Twitter, его немного сложнее очистить, а это означает, что контент не всегда виден.
Для этого нам нужно будет использовать что-то вроде Selenium, о чем мы здесь не будем говорить. Во-вторых, Twitter предоставляет несколько API, которые, вероятно, будут более полезны в этих случаях.Вместо этого вот «поддельный твиттер», созданный специально для этого упражнения.
http://ethans_fake_twitter_site.surge.sh/
На указанном выше сайте «Поддельный Твиттер» мы можем увидеть подборку реальных твитов Джимми Фэллона за период с 2013 по 2017 год. Если мы перейдем по указанной выше ссылке, мы должны кое-что увидеть вот так:
Здесь, если мы хотим очистить все твиты, есть несколько вещей, связанных с каждым твитом, которые мы также можем очистить:
- Твит
- Автор (JimmyFallon)
- Дата и время
- Количество лайков
- Количество акций
Первый вопрос, который нужно задать перед тем, как мы начнем анализировать, — это то, чего мы хотим достичь.Например, если бы все, что мы хотели сделать, это знать, когда произошло большинство твитов, единственными данными, которые нам действительно нужно очистить, была бы дата.
Однако для удобства мы продолжим и очистим твит целиком. Давайте снова откроем Инструменты разработчика в Chrome, чтобы посмотреть, как они структурированы, и посмотрим, есть ли какие-либо селекторы, которые были бы полезны при сборе этих данных:Под капотом похоже, что каждый элемент здесь находится в нем собственный класс. Автор находится в теге
с классом с именем «author».Твит находится в теге
с классом с именем «content». Отметки «Нравится» и «Поделиться» также находятся в тегах
с классами с именами «нравится» и «поделился». Наконец, наша дата / время находится в теге
с классом dateTime.
Если мы воспользуемся тем же форматом, который мы использовали выше, чтобы очистить этот сайт и распечатать результаты, мы, вероятно, увидим что-то похожее на это:
То, что мы здесь сделали, просто выполняет шаги, описанные ранее. Мы начали с импорта bs4 и запросов, а затем установили URL, RESPONSE и CONTENT в качестве переменных и распечатали переменную содержимого.
Данные, которые мы здесь напечатали, бесполезны. Мы просто распечатали всю необработанную структуру HTML. Мы бы предпочли преобразовать извлеченные данные в пригодный для использования формат.4.b Селекторы в Beautiful Soup
Чтобы получить твит, нам нужно использовать селекторы, которые предоставляет Beautiful Soup. Давайте попробуем следующее:
tweet = content.findAll ('p', attrs = {"class": "content"}). Text
print tweetВместо того, чтобы печатать весь контент, мы попытаемся получить твиты .Давайте еще раз посмотрим на наш предыдущий пример html и посмотрим, как он соотносится с приведенным выше фрагментом кода:
В предыдущем фрагменте кода в качестве селектора используется атрибут класса content. В основном
«p», attrs = {«class»: «content»}говорит: «Мы хотим выбрать все теги абзацев, но только те, которые имеют класс с именем« content ».
Теперь, если бы мы остановились на этом и распечатали результаты, мы бы получили бы весь тег, идентификатор, класс и контент.
Результат будет выглядеть так:Но все, что нам действительно нужно, это содержание или текст тега: Сегодня вечером: @MichaelKeaton, @ninadobrev, музыка от @The_xx и многое другое! #FallonTonight
Таким образом,
.textсообщает Python, что если мы найдем тегс классом «content», мы выберем только текстовое содержимое этого тега.
Однако, когда мы запускаем эту строку кода, мы только получить самый первый твит, а не все твиты.Это кажется немного нелогичным, поскольку мы использовали метод
findAll ().Чтобы получить все твиты, а не только первый, нам нужно перебрать контент и выбрать его в цикле, например:для твита в content.findAll ('p', attrs = { "class": "content"}):
print tweet.text.encode ('utf-8')Теперь, когда мы перебираем контент, мы сможем просмотреть все твиты. Потрясающе!
4.c Преобразование очищенных данных в JSON
Следующим шагом в этом процессе, прежде чем мы фактически сохраним данные, является их преобразование в JSON.
JSON расшифровывается как JavaScript Object Notation. В Python используется терминология Dicts. В любом случае эти данные будут в форме пар ключ / значение. В нашем случае эти данные могут выглядеть так:tweetObject = {
"author": "JimmyFallon",
"date": "28.02.2018",
"tweet": "Не пропустите сегодняшнюю show! ",
" лайков ":" 250 ",
" акций ":" 1000 "
}Каждый твит будет иметь этот формат и может храниться в массиве. Это позволит нам позже проанализировать данные.Мы могли бы быстро запросить у Python все даты или все лайки, или подсчитать, сколько раз слово «шоу» используется во всех «твитах». Хранение данных в удобном для использования виде, как это, будет ключом к чему-то интересному с данными позже. Если мы прокрутим назад и снова посмотрим на структуру HTML, мы можем заметить, что каждый твит находится в элементе
с именем класса «tweetcontainer». Каждый автор, твит, дата и т. Д. Будут внутри одного из этих контейнеров. Ранее мы перебирали все данные и выбирали твиты из каждого элемента. Почему бы нам не сделать то же самое, а вместо этого перебрать каждый контейнер, чтобы мы могли выбрать индивидуальную дату, автора и твит для каждого из них. Наш код может выглядеть примерно так:для твита в content.findAll ('div', attrs = {"class": "tweetcontainer"}):
tweetObject = {
"author": "JimmyFallon",
"date ":" 28.02.2018 ",
" tweet ":" Не пропустите вечернее шоу! ",
" лайков ":" 250 ",
" поделится ":" 1000 "
}Однако вместо эти данные, мы хотим выбрать отдельные данные из каждого твита для создания нашего объекта.Вместо этого конечный результат будет:
из bs4 import BeautifulSoup
запросов на импортtweetArr = []
для твита в content.findAll ('div', attrs = {"class": "tweetcontainer"}):
tweetObject = {
"author": tweet.find ('h3', attrs = {"class": "author"}). Text.encode ('utf-8'),
"date": tweet.find ('h5' , attrs = {"class": "dateTime"}). text.encode ('utf-8'),
"tweet": tweet. find ('p', attrs = {"class": "content"}) .text.encode ('utf-8'),
"нравится": tweet.find ('p', attrs = {"class": "like"}).text.encode ('utf-8'),
"share": tweet.find ('p', attrs = {"class": "share"}). text.encode ('utf-8')
}
распечатать tweetObjectОтлично! Все наши данные представлены в удобном и удобном формате. Хотя до этого момента все, что мы делали, это распечатывали результаты. Давайте добавим последний шаг и сохраним данные в виде файла JSON.
4.d Сохранение данных
Для этого добавим еще один импорт в наш код вверху и импортируем json. Это основная библиотека, поэтому нам не нужно устанавливать ее через pip, как мы делали другие пакеты.Затем, пройдя цикл по нашим данным и построив объект tweetообъекта из каждого элемента, мы добавим этот объект или dict в наш tweetArr, который будет массивом твитов. Наконец, мы воспользуемся преимуществами библиотеки json и напишем файл json, используя наш массив твитов в качестве данных для записи.
Окончательный код может выглядеть так:из bs4 import BeautifulSoup
запросов на импорт
import jsontweetArr = []
для твита в content.findAll ('div', attrs = {"class": "tweetcontainer"}) :
tweetObject = {
"автор": tweet.find ('h3', attrs = {"class": "author"}). text.encode ('utf-8'),
"date": tweet.find ('h5', attrs = {"class": "dateTime"}). text.encode ('utf-8'),
"tweet": tweet.find ('p', attrs = {"class": "content"}). text.encode ('utf- 8 '),
"лайков": tweet.find (' p ', attrs = {"class": "like"}). Text.encode (' utf-8 '),
"share": tweet.find ( 'p', attrs = {"class": "share"}). text.encode ('utf-8')
}
tweetArr.append (tweetObject)
с открытым ('twitterData.json', 'w') как outfile:
json.dump (tweetArr, outfile)При запуске Python должен был сгенерировать и записать новый файл с именем twitterData.Теперь давайте попробуем проанализировать эти данные!
5. Анализ данных JSON
Давайте вернемся к нашему дереву файлов и откроем файл анализа (parsedata.
py), который должен быть пустым.Так же, как мы вызвали json и открыли файл json на предыдущем шаге, на этом шаге мы сделаем то же самое. Однако теперь вместо записи в файл json мы хотим читать из только что созданного файла json.
с open ('twitterData.json') как json_data:
jsonData = json.load (json_data)Теперь мы можем использовать переменную jsonData.Он должен содержать всю информацию, которую мы скопировали, но в формате JSON. Давайте начнем с чего-нибудь простого, напечатав все даты всех твитов:
для i в jsonData:
print i ['date']Запустив эту команду, мы должны увидеть сгенерированный список всех дат всех твиты.
Еще одна забавная вещь, которую можно сделать, - это посмотреть, как часто определенные слова появляются в твитах. Например, мы могли бы запустить запрос, чтобы узнать, как часто «Обама» появляется в твитах:
для i в jsonData:
, если «obama» в i ['твитнуть »].lower ():
print iЭто покажет нам весь объект твита для каждого твита, в котором упоминается «обама».
Довольно круто, правда? Очевидно, возможности безграничны. Теперь должно быть ясно, насколько легко эффективно очистить данные из Интернета, а затем преобразовать их в пригодный для использования формат для анализа. Фантастика!Если у вас есть отзывы или вопросы, не стесняйтесь обращаться к нам!
Связанные
Теги
Присоединяйтесь к Hacker NoonСоздайте бесплатную учетную запись, чтобы разблокировать свой собственный опыт чтения.
Плагин автоматического парсера и обходчика контента WordPress
Вы уже можете скопировать содержимое любого сайта на свой собственный сайт WordPress вручную без каких-либо инструментов. Scrapes - это просто автоматический плагин для парсера WordPress, который позволяет автоматизировать этот процесс. Другими словами, этот вопрос не относится к Царапинам, и нет однозначного ответа на «Да» или «Нет». На самом деле ответ различается в зависимости от сайта-источника и вашего предполагаемого использования контента.
- Некоторые из них стремятся привлечь больше пользователей, делясь своим контентом с помощью таких систем обмена контентом, как RSS (Rich Site Summary) или API (Application Programming Interface).
- Некоторые из них позволяют публиковать часть своего контента, просят дать им обратную ссылку для просмотра остального и таргетинга на большее количество обращений.
- Некоторые в обмен на публикацию своих продуктов на вашем сайте платят вам в рамках своих программ аффилированного маркетинга и стремятся продавать больше.
- Некоторые позволяют публиковать свой контент, кроме коммерческого использования.
- Некоторые ссылаются на дополнительные методы защиты, чтобы не соскрести их содержимое.
Хотя копирование содержания любого веб-сайта полностью лежит на вас, наши рекомендации, как не делать что-либо незаконное и избегать штрафных санкций Google за дублирование контента, заключаются в следующем.
- В случае необходимости, вы можете связаться с владельцем и запросить разрешение на публикацию контента на вашем сайте.
- Используя плагин SEO, который позволяет определять канонический URL-адрес, вы можете указать, какой источник используется.
- Измените контент на другой язык с помощью функции перевода или извлеките новый контент с помощью сервисов прядильщика контента.
- С помощью функции шаблона вы можете добавить кредитную информацию или обратную ссылку, направленную на исходный URL, в конец контента, например, в режиме плагина автоматической публикации WordPress.
- Вы можете опубликовать часть содержимого, сократив ее с помощью функции «Найти и заменить» вместо публикации всего содержимого.
- Вы можете извлечь содержимое в статусе «Черновик» и опубликовать его после внесения изменений.
Очистка данных из списка URL-адресов путем создания простого парсера
Очистка веб-страниц может быть выполнена путем создания веб-сканера на Python. Перед написанием краулера на основе Python вам необходимо изучить источник и узнать структуру целевого веб-сайта.
И, конечно, вам нужно изучить Python. Будет намного проще, если вы уже умеете кодировать. Но техническому новичку очень сложно научиться всему с нуля. Поэтому мы создаем наше приложение Octoparse, чтобы помочь людям, которые мало или ничего не знают о кодировании, легко очистить любые веб-данные.В этом руководстве мы узнаем, как создать самый простой и легкий парсер для очистки списка URL-адресов без какого-либо кодирования. Этот метод лучше всего подходит для таких начинающих, как некоторые из вас. (Предположим, что Octoparse уже установлен на вашем компьютере.Если это не так, скачайте здесь)
Это руководство проведет вас через следующие шаги:
1. Создайте «Элемент цикла» в рабочем процессе
2. Добавьте список URL-адресов в созданный «Элемент цикла»
3. Щелкните, чтобы извлечь точки данных с одной веб-страницы
4. Запустите скребок для установки
5.
Экспорт данных извлечен 1.Создайте «Элемент цикла» в рабочем процессе
После настройки основной информации для вашей задачи перетащите «Элемент цикла» в конструктор рабочего процесса.
2. Добавьте список URL-адресов в созданный «Элемент цикла»
После создания «элемента цикла» в конструкторе рабочего процесса добавьте список URL-адресов в «элемент цикла», чтобы создать шаблон для навигации по каждой веб-странице.
· Выберите режим цикла «Список URL-адресов» в расширенных параметрах шага «Элемент цикла».
· Скопируйте и вставьте все URL-адреса в текстовое поле «Список URL-адресов».
· Нажмите «ОК» и затем сохраните конфигурацию.
Примечание:
1) Все URL-адреса должны иметь одинаковый макет
2) Добавьте не более 20 000 URL
3) Вам нужно будет вручную скопировать и вставить URL-адреса в текстовое поле «Список URL-адресов».
4) После ввода всех URL-адресов действие «Перейти к веб-странице» будет автоматически создано в «Элементе цикла».
3. Щелкните, чтобы извлечь точки данных с одной веб-страницы
Когда веб-страница полностью загрузится, щелкните точку данных на веб-странице, чтобы извлечь нужные данные.
· Щелкните нужные данные и выберите «Извлечь данные» (действие «Извлечь данные» будет создано автоматически.)
4. Запустите скребок для установки
Скребок создан. Запустите задачу с помощью «Локального извлечения» или «Извлечения из облака».
В этом руководстве мы запускаем парсер с «извлечением облака».
· Нажмите «Далее», а затем «Облачное извлечение», чтобы запустить парсер на облачной платформе.
Примечание:
1) Вы можете закрыть приложение или компьютер, когда запускаете парсер с «Cloud Extraction».
Просто сядьте и расслабьтесь. Затем вернитесь за данными. Не нужно беспокоиться о перебоях в Интернете или ограничениях оборудования.
2) Вы также можете запустить парсер с «локальным извлечением» (на вашем локальном компьютере).
5. Экспорт извлеченных данных
· Нажмите «Просмотреть данные», чтобы проверить извлеченные данные.
· Выберите «Экспортировать текущую страницу» или «Экспортировать все» для экспорта извлеченных данных
Примечание:
1) Octoparse поддерживает экспорт данных в Excel (2003), Excel (2007), CSV или доставку данных в вашу базу данных.
2) Вы также можете создавать Octoparse API и получать доступ к данным. См. Дополнительную информацию на http://advancedapi.octoparse.com/help
.Теперь мы узнали, как очищать данные из списка URL-адресов, создав простой парсер без какого-либо кодирования! Очень просто, правда? Попробуйте сами!
Демо-данные извлечены ниже:
(я также прилагаю демонстрационную задачу и демонстрационную задачу, экспортированную в excel.
 Возьмем приведенный ниже гипотетический пример, в котором мы могли бы создать веб-парсер, который будет заходить в твиттер и собирать содержимое твитов.
Возьмем приведенный ниже гипотетический пример, в котором мы могли бы создать веб-парсер, который будет заходить в твиттер и собирать содержимое твитов. Чтобы узнать, как определить, где находится информация на странице, требуется небольшое исследование, прежде чем мы создадим парсер.
Чтобы узнать, как определить, где находится информация на странице, требуется небольшое исследование, прежде чем мы создадим парсер.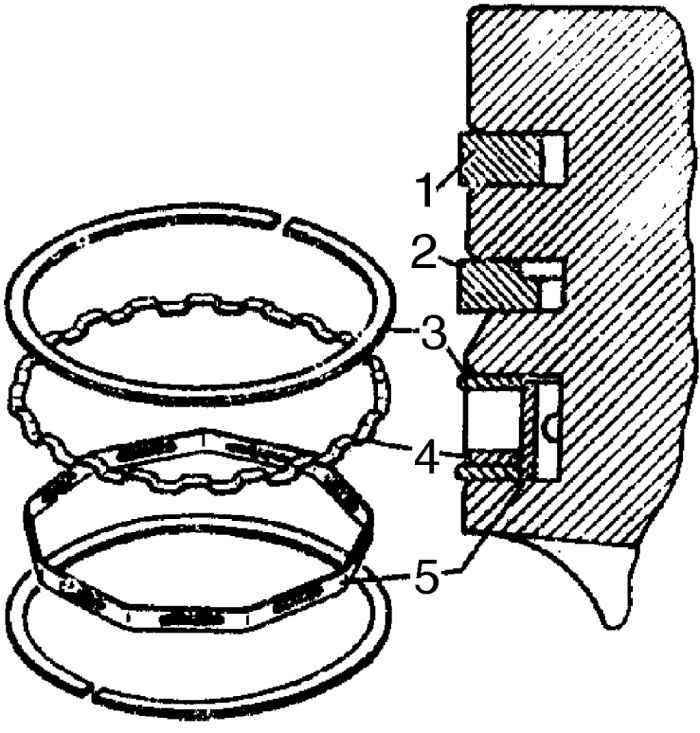 В приведенном выше примере мы могли бы захотеть сохранить данные, которые мы собрали из твитов, чтобы мы могли видеть, когда твиты были наиболее частыми, каковы были наиболее распространенные темы или какие люди упоминались чаще всего.
В приведенном выше примере мы могли бы захотеть сохранить данные, которые мы собрали из твитов, чтобы мы могли видеть, когда твиты были наиболее частыми, каковы были наиболее распространенные темы или какие люди упоминались чаще всего. В этом примере мы сосредоточимся на использовании Python и сопутствующей ему библиотеки Beautiful Soup. Здесь также важно отметить, что для создания успешного веб-парсера нам необходимо хотя бы в некоторой степени быть знакомыми со структурами HTML и форматами данных, такими как JSON.
В этом примере мы сосредоточимся на использовании Python и сопутствующей ему библиотеки Beautiful Soup. Здесь также важно отметить, что для создания успешного веб-парсера нам необходимо хотя бы в некоторой степени быть знакомыми со структурами HTML и форматами данных, такими как JSON. В других браузерах, таких как Firefox и Internet Explorer, также есть инструменты разработчика, но в этом примере я буду использовать Chrome. Если вы нажмете на три вертикальные точки в правом верхнем углу браузера, затем выберите «Дополнительные инструменты», а затем «Инструменты разработчика», вы увидите всплывающую панель, которая выглядит следующим образом:
В других браузерах, таких как Firefox и Internet Explorer, также есть инструменты разработчика, но в этом примере я буду использовать Chrome. Если вы нажмете на три вертикальные точки в правом верхнем углу браузера, затем выберите «Дополнительные инструменты», а затем «Инструменты разработчика», вы увидите всплывающую панель, которая выглядит следующим образом:

 Мы могли бы начать работу за считанные минуты с помощью веб-парсера Python. Если вы еще не установили Python, сделайте это сейчас:
Мы могли бы начать работу за считанные минуты с помощью веб-парсера Python. Если вы еще не установили Python, сделайте это сейчас: Это будут данные, полученные из Интернета. Если мы подумаем о том, каким может быть наш рабочий процесс для этого проекта, мы можем представить, что он выглядит примерно так:
Это будут данные, полученные из Интернета. Если мы подумаем о том, каким может быть наш рабочий процесс для этого проекта, мы можем представить, что он выглядит примерно так: Библиотека запросов позволяет нам делать запросы к URL-адресам и получать доступ к данным на этих HTML-страницах. Beautiful Soup содержит несколько простых способов идентифицировать теги, которые мы обсуждали ранее, прямо из нашего скрипта Python.
Библиотека запросов позволяет нам делать запросы к URL-адресам и получать доступ к данным на этих HTML-страницах. Beautiful Soup содержит несколько простых способов идентифицировать теги, которые мы обсуждали ранее, прямо из нашего скрипта Python. В OS X мы откроем папку Applications, а затем папку Utilities. Откройте приложение Терминал. Мы также можем добавить это в нашу док-станцию.
В OS X мы откроем папку Applications, а затем папку Utilities. Откройте приложение Терминал. Мы также можем добавить это в нашу док-станцию. Для этого мы снова воспользуемся терминалом, на этот раз установив библиотеки с помощью установщика pip.Выполним следующие команды:
Для этого мы снова воспользуемся терминалом, на этот раз установив библиотеки с помощью установщика pip.Выполним следующие команды: Следует помнить, что некоторые библиотеки довольно большие и могут занимать много места. Развернуть сайт, над которым мы работали, может быть сложно, если на нем слишком много больших пакетов.
Следует помнить, что некоторые библиотеки довольно большие и могут занимать много места. Развернуть сайт, над которым мы работали, может быть сложно, если на нем слишком много больших пакетов. Если мы напечатаем все содержимое ответа, мы получим все содержимое на всей странице запрашиваемого URL.
Если мы напечатаем все содержимое ответа, мы получим все содержимое на всей странице запрашиваемого URL. Для этого нам нужно будет использовать что-то вроде Selenium, о чем мы здесь не будем говорить. Во-вторых, Twitter предоставляет несколько API, которые, вероятно, будут более полезны в этих случаях.
Для этого нам нужно будет использовать что-то вроде Selenium, о чем мы здесь не будем говорить. Во-вторых, Twitter предоставляет несколько API, которые, вероятно, будут более полезны в этих случаях. Однако для удобства мы продолжим и очистим твит целиком. Давайте снова откроем Инструменты разработчика в Chrome, чтобы посмотреть, как они структурированы, и посмотрим, есть ли какие-либо селекторы, которые были бы полезны при сборе этих данных:
Однако для удобства мы продолжим и очистим твит целиком. Давайте снова откроем Инструменты разработчика в Chrome, чтобы посмотреть, как они структурированы, и посмотрим, есть ли какие-либо селекторы, которые были бы полезны при сборе этих данных: Данные, которые мы здесь напечатали, бесполезны. Мы просто распечатали всю необработанную структуру HTML. Мы бы предпочли преобразовать извлеченные данные в пригодный для использования формат.
Данные, которые мы здесь напечатали, бесполезны. Мы просто распечатали всю необработанную структуру HTML. Мы бы предпочли преобразовать извлеченные данные в пригодный для использования формат. Результат будет выглядеть так:
Результат будет выглядеть так: JSON расшифровывается как JavaScript Object Notation. В Python используется терминология Dicts. В любом случае эти данные будут в форме пар ключ / значение. В нашем случае эти данные могут выглядеть так:
JSON расшифровывается как JavaScript Object Notation. В Python используется терминология Dicts. В любом случае эти данные будут в форме пар ключ / значение. В нашем случае эти данные могут выглядеть так: Почему бы нам не сделать то же самое, а вместо этого перебрать каждый контейнер, чтобы мы могли выбрать индивидуальную дату, автора и твит для каждого из них. Наш код может выглядеть примерно так:
Почему бы нам не сделать то же самое, а вместо этого перебрать каждый контейнер, чтобы мы могли выбрать индивидуальную дату, автора и твит для каждого из них. Наш код может выглядеть примерно так: find ('p', attrs = {"class": "content"}) .text.encode ('utf-8'),
find ('p', attrs = {"class": "content"}) .text.encode ('utf-8'),  Окончательный код может выглядеть так:
Окончательный код может выглядеть так: py), который должен быть пустым.
py), который должен быть пустым. Довольно круто, правда? Очевидно, возможности безграничны. Теперь должно быть ясно, насколько легко эффективно очистить данные из Интернета, а затем преобразовать их в пригодный для использования формат для анализа. Фантастика!
Довольно круто, правда? Очевидно, возможности безграничны. Теперь должно быть ясно, насколько легко эффективно очистить данные из Интернета, а затем преобразовать их в пригодный для использования формат для анализа. Фантастика!

 И, конечно, вам нужно изучить Python. Будет намного проще, если вы уже умеете кодировать. Но техническому новичку очень сложно научиться всему с нуля. Поэтому мы создаем наше приложение Octoparse, чтобы помочь людям, которые мало или ничего не знают о кодировании, легко очистить любые веб-данные.
И, конечно, вам нужно изучить Python. Будет намного проще, если вы уже умеете кодировать. Но техническому новичку очень сложно научиться всему с нуля. Поэтому мы создаем наше приложение Octoparse, чтобы помочь людям, которые мало или ничего не знают о кодировании, легко очистить любые веб-данные. Экспорт данных извлечен
Экспорт данных извлечен 

